





Breaking News: October 27, 2025
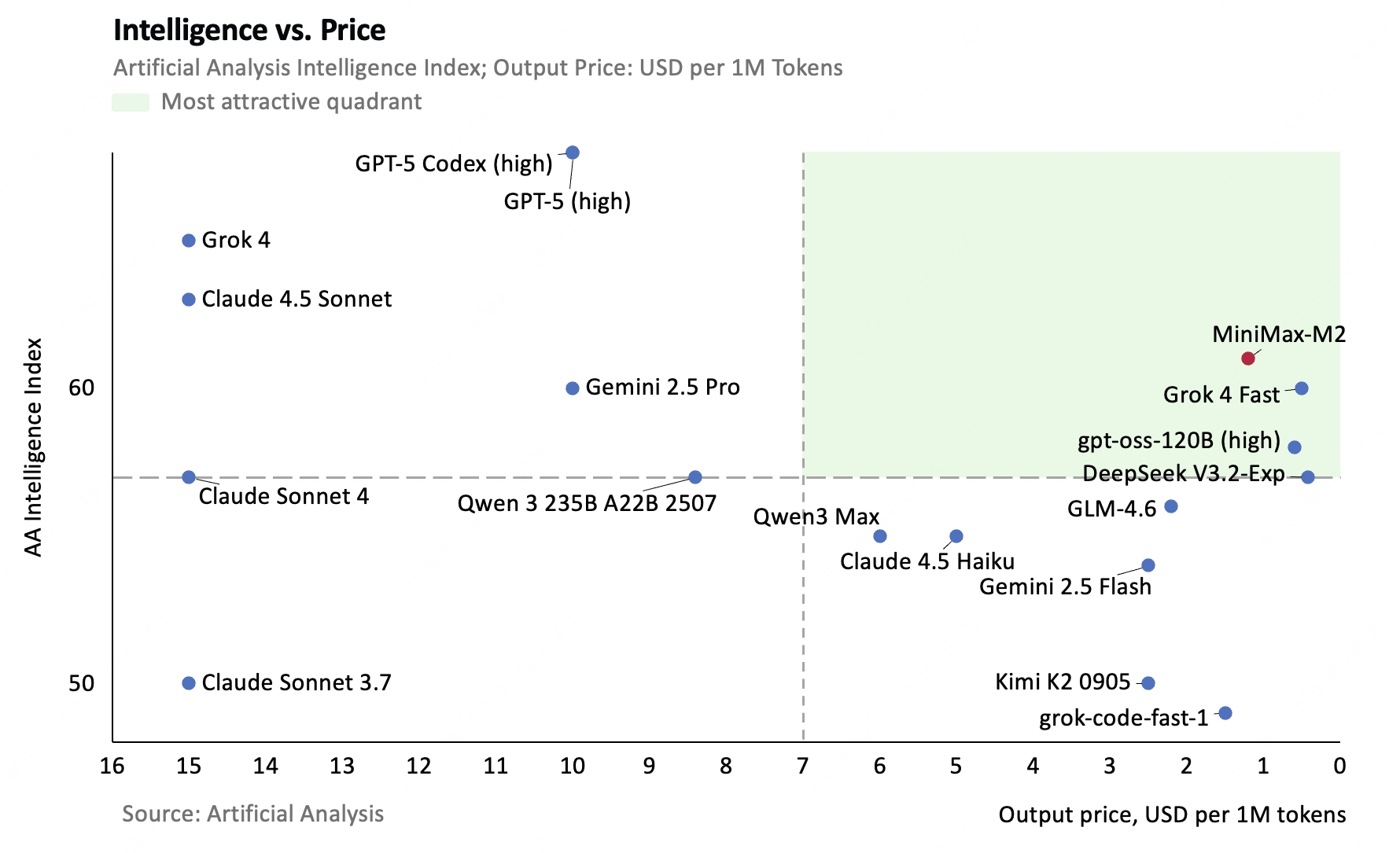
MiniMax M2 is a revolutionary large language model from Shanghai-based AI startup MiniMax that achieves a 61% intelligence score on Artificial Analysis benchmarks, placing it in the top 5 globally and making it the highest-ranked open-source model available. With full weights released under the MIT license on Hugging Face, M2 democratizes access to frontier AI capabilities.

Technical Specifications
Architecture
Mixture-of-Experts (MoE) with 230B total parameters and 10B active parameters per inference
Context Window
204,800 tokens for processing extensive documents and codebases
Inference Speed
~1,500 tokens/second, approximately 2x faster than Claude Sonnet
Deployment
Runs efficiently on 4xH100 GPUs at FP8 precision
License
MIT license with full open-source availability
Efficiency
Activates only 10B parameters per request while maintaining 230B model knowledge
Core Strengths
🤖 Agent-Native Design
M2 is explicitly engineered for agentic workflows and automation, with superior performance on tool use and instruction following benchmarks (Tau2 Bench, IFBench). The model excels at multi-step planning, tool orchestration, and autonomous task execution.
💻 Coding Excellence
Strong performance across SWE-Bench (69.4), Terminal-Bench (46.3), and HumanEval (~85% pass@1) demonstrates reliable code generation capabilities. M2 supports complete code-run-test-repair loops with multi-file editing and debugging.
🔧 Tool Integration
Robust function calling and tool integration through OpenAI-compatible and Anthropic-compatible APIs, plus Model Context Protocol (MCP) support for terminal, browser, and Python tool integrations.

Performance Comparisons
🆚 vs. Closed-Source Models
| Model | Intelligence Score | Relative Cost | Speed | Status |
|---|---|---|---|---|
| MiniMax M2 | 61% | 100% (baseline) | ~1,500 tok/s | Open Source |
| Claude 4.5 Sonnet | 63% | 1,250% (12.5x) | ~750 tok/s | Closed |
| GPT-5 | 68% | ~833% (8.3x) | ~1,000 tok/s | Closed |
| Gemini 2.5 Pro | 60% | ~500% (5x) | ~900 tok/s | Closed |
Key Insight
M2 scores 61% vs. Claude’s 63% (near-parity), but costs only 8% as much and runs 2x faster. It even outperforms Gemini 2.5 Pro (61% vs. 60%) while being fully open-source!
🏆 vs. Open-Source Models
- DeepSeek V3: Larger capacity (671B total, 37B active) provides advantages in generalist tasks, but M2 excels at agentic workflows and tool use with superior efficiency
- Qwen3 235B: M2 achieves higher overall intelligence scores, with specialization in coding and agents vs. Qwen’s multimodal strengths
M2 holds the #1 position among all open-weights models on independent benchmarks.
Pricing and Economics
Input Tokens
per million tokens
- Lowest cost in class
- Same quality as premium models
- No hidden fees
Output Tokens
per million tokens
- 8% of Claude’s cost
- 2x faster delivery
- Top 5 performance
Self-Hosting
zero per-token costs
- Full control
- MIT licensed
- Deploy anywhere
Cost Comparison Example (100K input + 50K output)
- MiniMax M2: $0.09
- Claude Sonnet 4.5: ~$1.05 (11.7x more expensive)
- GPT-5: ~$0.75 (8.3x more expensive)
Free Trial: Extended free access through November 7, 2025 (UTC)
Primary Use Cases
Software Development
Code generation, debugging, refactoring, and multi-file editing with IDE integration (Cursor, Claude Code, Cline)
Autonomous Agents
Multi-step workflows, tool orchestration, API integration, and business process automation
Research & Analysis
Long-document analysis, literature review, and technical specification evaluation using 204K token context
Terminal Workflows
DevOps automation, script execution, and command-line tool integration
Key Limitations
Important Considerations
- Verbosity: M2 generates approximately 120 million tokens for tasks where competitors use 60-80 million, requiring prompt engineering and length controls
- Generalist Performance: May underperform DeepSeek V3 and Qwen3 on some general reasoning tasks due to specialization trade-offs
- Multimodal Gaps: Primarily text-only with limited vision capabilities compared to multimodal leaders
- Track Record: As a late October 2025 release, M2 has limited production deployment history
Deployment Options
Self-Hosting
Available via Hugging Face with vLLM and SGLang inference server support
API Access
MiniMax official platform, plus third-party aggregators (CometAPI, Straico, AIML API)
Integration
OpenAI-compatible and Anthropic-compatible SDKs for drop-in replacement
Why M2 Matters
MiniMax M2 represents a paradigm shift in AI accessibility, proving that open-source models can achieve frontier-class performance while operating at a fraction of proprietary model costs. By delivering top-5 global intelligence at 8% of Claude’s price and 2x its speed, M2 democratizes advanced AI capabilities for startups, researchers, and developers worldwide.
The model’s success validates an efficiency-first development philosophy that prioritizes practical deployment economics alongside raw capability, potentially influencing how the entire AI industry approaches model development going forward. For organizations building coding assistants, autonomous agents, or automation systems, M2 offers an unmatched combination of performance, cost-effectiveness, and open availability.
The Bottom Line
If you’re building AI applications, especially coding tools or autonomous agents, MiniMax M2 should be on your radar. It’s not just another model—it’s a fundamental shift in what’s possible with open-source AI. The economics alone (8% of Claude’s cost, 2x speed) make it compelling, but the top-5 performance seals the deal.